
唐林垚 中国社会科学院法学研究所助理研究员,法学博士、博士后。
内容摘要
欧盟《通用数据保护条例》(gdpr)第22条应作权利而非禁令解,由此产生的“脱离自动化决策权”存在与“更正权”竞合之表象、与“获解释权”补强之曲解以及与“被遗忘权”混同之误判。界定该权利应把握两条主线:(1)gdpr序言第71条赋予数据主体的三种基本权利乃相互并列而非互为因果;(2)权利内涵随技术发展嬗变,在基于数据库编码的计算机自动化场景为脱离数据采集,在基于机器学习的算法自动化场景为脱离用户侧写,在基于神经网络的超级自动化场景为脱离平台交互。破除权利失语的关键在于适用条件去场景化以及自甘风险式的豁免进路让位于实现公共利益所必须的法定许可。若不囿于既定框架,陈情权和离线权的重构思路各有合理之处,但应防范可能产生过高的社会成本。
关键词:脱离自动化决策权 更正权 获解释权 被遗忘权 豁免规则 自甘风险
自动化决策是与自然人决策相对立的概念,意指利用计算机技术(1980-2000)、算法程序(2000-2020)、深度学习或神经网络(2020+)替代自然人处理关键数据,凭借其自动生成对数据主体具有法律效果的决策的行为。欧盟《通用数据保护条例》(下简称gdpr)第22条第1款允许数据主体“脱离自动化决策”,国内主流学者将其翻译为“反对自动化决策”或“不受自动化处理的决定的限制”,但依照原文“有权不成为自动化决策支配对象(not to be subject to a decision based solely on automated processing)”之表述,将其译为“脱离自动化决策”更为妥当。第22条第1款虽然在文义上赋予了数据主体脱离完全依靠自动化处理对其做出的具有法律后果决策的权利,可是具体该如何脱离、能够脱离到何种程度,仅凭第22条无从知晓。
我国虽未进行相关法律移植,但在实践中以行胜于言的方式,一定程度上实现了上述“脱离自动化决策权”的精神内涵。一个贴切的例子是:政府部门允许个人在健康码的结果同实际情况不符时,拨打12345热线发起纠错申请,经县级防控指挥部核实确认后,即可修改风险判定结果。该实例向我们充分展示了三个深刻的现实:其一,在疫情防控常态化的背景之下,数据主体与自动化决策“脱钩”将寸步难行,即便行使了“脱离自动化决策权”,也不过是对不公正结果的暂时纠偏,不能、也不可能完全脱离自动化决策;其二,即便效果有限,“脱离自动化决策权”也是一种值得保护的法律权利,因为无论自动化技术有多么先进,出错在所难免,此时,适当的人工介入乃数据主体脱离自动化决策失误的补救之道;其三,“脱离自动化决策权”是一种颇为特殊的权利,有着不同于一般请求权的行使要件和适用场景。例如,gdpr第16条规定了数据主体的“更正权”,允许数据主体在不违反处理目的的前提下,完善或更正不充分的个人数据。我国网络安全法也有类似的规定,且被最新颁布的民法典所吸纳,成为人格权编中的重要条款。似乎,拨打12345发起健康码纠错申请,是当事人在行使法定的更正权。对此,需要厘清的是,无论是欧盟还是我国,数据主体行使更正权可以更正的对象,只能是个人数据而非数据经自动化处理后产生的决策结果,两者有着指向性的区别。就行权拟取得的法律效果而言,“更正权”甚至算不上最低程度的“脱离自动化决策权”。
在自动化应用结构性嵌入社会运营的大趋势下,“脱离自动化决策权”绝非请求人工介入、修改决策结果这么简单,否则gdpr第22条大费周章、甚至有些迂回曲折的立法尝试将毫无必要。“脱离自动化决策权”的内涵和外延究竟是什么?与gdpr保障数据主体的其他权利有何关联和区别?正确理解“脱离自动化决策权”背后的核心价值与理论基础,将对我国未来人工智能立法带来重要启示。

一
从dpid到gdpr:历史沿革与理论争议
“脱离自动化决策权”并非gdpr首创,始见于1995年欧盟《个人数据保护指令》(下简称dpid)第15条第1款:“数据主体享有免受基于用户侧写的完全自动化决策的权利”。该权利的行使以两个必要条件为前提:(1)自动化决策必须对数据主体造成具有法律后果的重大影响;(2)用户侧写完全由自动化处理实现。
(一)dpid第15条的历史遗留问题
dpid是gdpr的前身,两者前后间隔23年,在此期间,有两个事实需要注意。其一,自动化决策实现了技术层面的飞跃,逐步改变了探讨“脱离自动化决策权”的语境。在制定dpid并推行的20世纪90年代,自动化决策主要指基于数据库编码的计算机自动化,即利用计算机替代自然人实现唯手熟尔的重复性基础工作和流程性工作。2000年之后,基于数据库编码的计算机自动化逐渐让位于基于机器学习的算法自动化,其实质是作为编程理论典范的透过规则本原寻求逻辑。大数据加持机器学习模型,在范围不确定的环境中进行规律挖掘或模式识别,替代自然人实现温故而知新的基础性预测工作与规范性鉴别工作。gdpr自2018年5月开始生效,基于机器学习的算法自动化正逐步向基于神经网络的超级自动化迈进。随着数据平台的开源共享以及机器学习模型的重叠交互,今天的自动化决策已经渐次突破立普斯基所称“自然人可以、机器人不行”的推理和演绎的智能上限,其获得识辨特定时期的法律和社会运行宏观规律、以超乎常人的洞察力来提供制度解决方案或进行价值判断的奇点临近。在这个阶段,自动化决策将是“以任何信息技术设备为载体、以持续控制形式干预和引导日常社会互动的高度自主的精细化治理秩序”。括而言之,虽然用语均是“自动化决策”,但dpid的自动化决策概念仅仅涵盖了基于数据库编码的计算机自动化和基于机器学习的算法自动化,而gdpr的自动化决策概念囊括了迄今为止所有的自动化类型。这是笔者研究“脱离自动化决策权”需要顾及的权利适用范围变化。dpid和gdpr“脱离自动化决策权”的微妙差异如图一所示。
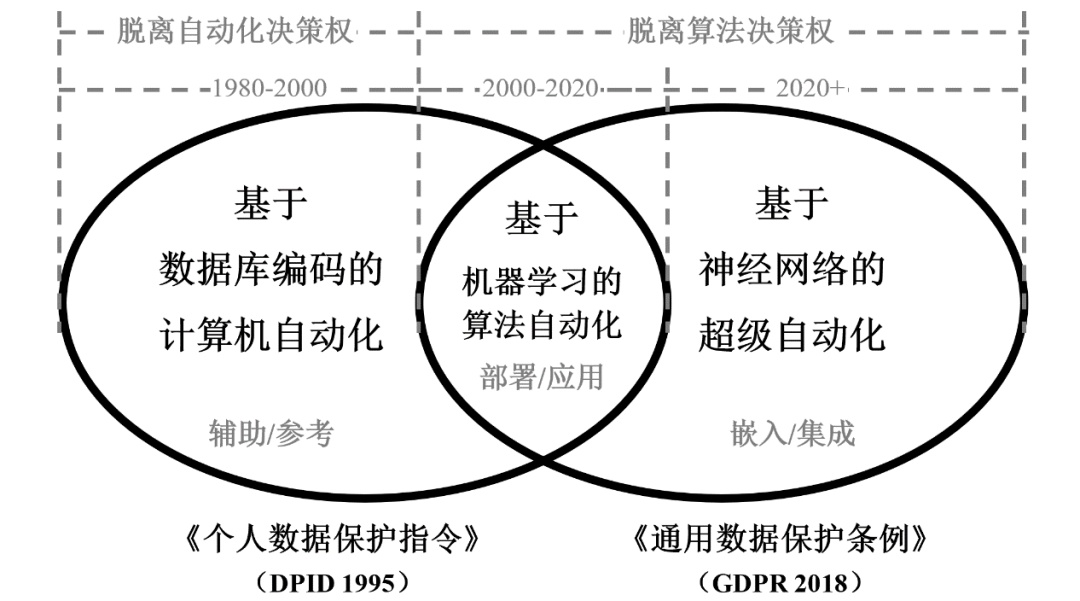
图一dpid和gdpr“脱离自动化决策权”之差异
其二,在dpid的整个生命周期内,第15条几乎完全处于休眠状态,但gdpr第22条依旧毅然决然地承袭了dpid第15条的规定,欧盟部长委员会于2018年通过的《关于个人数据处理的现代化保护公约》第9条也吸收了dpid第15条的相关规定。这或许意味着,在基于机器学习的算法自动化和基于神经网络的超级自动化大行其道的场景中,“脱离自动化决策权”更有适用和推广的必要。此前,“脱离自动化决策权”一直被戏称为dpid中的“二等权利”,因为在欧盟法院和各成员国法院的审判实践中,对抗双方从未就该权利的行使方式和法律效果展开有实质意义的辩论:“脱离自动化决策之诉”客观存在,但是双方总是聚焦于有争议的决策是否完全由自动化处理作出。例如,德国联邦法院在schufa案中裁定,资信考察系统输出的信用评价不属于dpid第15条所界定的完全无人工介入的自动化决策范畴,因为银行对其客户的信用评价实由自然人在自动化决策的“辅助”下完成;法国最高法院认为,执法者采取算法自动化系统进行裁决辅助,也不受dpid第15条的约束。前欧盟个体保障局在工作报告中指出,dpid第15条不是针对数据保护可以推而广之的一般性原则,而是针对特定自动化用户侧写的例外原则。伴随早期立法尝试铩羽而归的新问题是,gdpr第22条相对于dpid第15条的修改,能否让“脱离自动化决策权”焕发新的活力呢?
(二)规则演进与责任豁免
相较于dpid第15条,gdpr第22条的进步主要体现在以下三个方面:
其一,gdpr第22条对于特别敏感的个人数据给予了更多关注。第22条第4款规定,数据主体有权脱离依据涉及种族、民族历史、政治观念、工会、基因、自然人健康和性生活取向等数据形成的自动化决策。当且仅当数据控制者取得数据主体的明确同意或为实现公共利益所必须的法定许可时,才能不受干扰地处理此类敏感信息。由此可见,gdpr在个人数据类型化处理方面,具有比dpid更高的“颗粒度”。
其二,gdpr第22条拓展了“脱离自动化决策权”的行权范围,将未成年人的个人数据纳入特别保护对象。gdpr序言第38条指出,对未成年人个人数据的具体保护“尤其应适用于可能供机器学习模型生成用户侧写的数据”。序言第71条规定,基于用户侧写的自动化决策不作用于未成年人。相较之下,dpid并未就未成年人数据保护作出相关规定,也难从相关条款中推定未成年人是否应当享有“脱离自动化决策权”。对未成年人个人数据予以特殊保护,彰显出法律顺应市场需求与时俱进:随着互联网低龄时代的到来,九零后逐渐成为被舆论抛弃的“后浪”,零零后甚至一零后接过泛娱乐时代的大旗称雄网络。研究报告表明,零零后在餐饮、颜值经济等领域已经成为消费主力。数据控制者深谙“得零零后者得天下”“营销要从娃娃抓起”“先入为主培养消费习惯”的道理,在巨大商业利益的诱惑下,社交媒体、电商平台、视频网站对未成年数据趋之若鹜,竞相获取新生代个体的浏览历史、个人轨迹、消费记录、点赞和收藏列表等——精准针对未成年人的内容推送和价值观引导接踵而至,个中风险不言而喻。
其三,gdpr第22条拓展了“脱离自动化决策权”的适用范围,不再局限于dpid第15条“用户侧写完全由自动化处理实现”的行权限制。依照gdpr第22条“有权不成为自动化决策支配对象,包括用户侧写”的表述,似乎“自动化决策和用户侧写”共同构成了“脱离自动化决策权”的适用场景。也即是说,自动化决策无论是否以用户侧写实现,均可以引发数据主体行使“脱离自动化决策权”。反过来,用户侧写无论最终是否形成自动化决策,也终将受到gdpr第22条的约束。多名学者对此表达了异议,例如,门德萨和拜格雷夫认为,上述理解方式“违背了第22条的基本原理和立法背景,原文中的‘包括(including)’应当被解释为‘涉及(involving)’”。布尔坎认为,现今自动化决策必然涉及用户侧写,因此围绕第22条的争议可谓毫无必要。在笔者看来,反对派观点的学者至少犯了两个方面的错误:(1)未能深入考察自动化决策从最初基于数据库编码的计算机自动化,到近来基于机器学习的算法自动化,再到未来基于神经网络的超级自动化的跃迁过程,理所当然地认为自动化决策就是机器学习模型依照特定算法进行用户侧写形成的决策。实际上,自动化决策若由计算机检索数据库编码作出,就根本不涉及用户侧写的过程;若由神经网络的实现,用户侧写只是超级自动化决策的一个环节。(2)将gdpr第22条视为dpid第15条的单纯延续,未能深究措辞变化背后可能蕴藏的政策转向。概括适用到局部适用的条件变化,使得本来共同构成dpid第15条必要条件的自动化决策和用户侧写,在gdpr第22条中转变为充分条件。这也从正面证实了,dpid第15条仅允许数据主体在基于机器学习模型的算法自动化情形中行使“脱离自动化决策权”,而gdpr第22条可以同时适用于基于数据库编码的计算机自动化、基于机器学习的算法自动化乃至基于神经网络的超级自动化的所有情形,权利的适用范围被大大拓宽。
遗憾的是,虽有上述大刀阔斧的修改,自gdpr生效至今,丝毫未见“脱离自动化决策权”的复苏迹象。作为一项值得被保护的法律权利,为何“脱离自动化决策权”经常被遗忘、极少被行使、几乎与现实相“脱离”?这个问题的答案首先在于gdpr第22条相对于dpid第15条并未发生实质性修改的“适用条件”——数据主体有权请求脱离的,必须是“完全依靠自动化处理”产生的决策,这无疑极大地提高了“脱离自动化决策权”的适用门槛。无论是基于数据库编码的计算机自动化、还是基于机器学习的算法自动化,最低限度的人工介入实为不可避免,无论是出于维护机器运转之必须、还是确保数据结构化处理的一致性、亦或是确认机器学习模型未脱离“算法代码的缰绳”。针对适用门槛的权威解释长期缺位,进一步加剧了法条本身的模糊性,使得各参与方只能完全依照字面理解来调整自身的行为——既然一丁点自然人参与的“蛛丝马迹”便能推翻数据主体对gdpr第22条的信赖利益,“脱离自动化决策权”被完全架空的结果并不出人意料。
“脱离自动化决策权”的式微,还源于过于宽松的豁免条件。dpid第15条规定,数据主体主动要求并同意接受自动化决策服务时,将受到类似“禁止反言原则”的约束;在签订合同时,只要数据控制者或处理者采取了合适的措施来维护数据主体的合法权益,那么纯粹自动化决策的效力将不受挑战。gdpr实际上扩大了dpid的豁免范围,在第22条第2款中明确规定了“脱离自动化决策权”不适用的三种情形——当事人同意、法律授权以及合同约定。在上述三种豁免情形之外,gdpr第4款额外增加了需要和其他法条相互参照的行权限制条件。第22条第3款虽然对豁免条件进行了适当限缩,要求“数据控制者应当采取充分措施保障数据主体的权利、自由和正当利益,允许数据主体对数据控制者进行人工干涉,以便表达其观点和对决策表达异议的基本权利”。但是深究该款措辞不难看出,在豁免情形中,数据控制者依法应当保障数据主体的,只是“数据主体进行人工干涉”而非“数据主体请求数据控制者进行人工干涉”的权利,并且,数据主体进行人工干涉是为了表达其观点和对决策表达异议,具有“反对权”而非“脱离自动化决策权”的外观。易言之,“脱离自动化决策权”豁免条件生效,只需以对反对权的保障作为前提,而反对权已在gdpr第21条中得以单独规定:“出于公共利益、官方权威、控制者或第三方追求正当利益所进行的数据处理,包括根据相关规定进行的用户侧写,数据主体有权随时反对。”第22条第3款对第21条的简单重复并未实质性提高数据控制者的豁免门槛。
(三)“权利”与“禁令”的实质之争
在适用条件苛刻、豁免门槛过低的双重制约下,“脱离自动化决策权”赋予数据主体的权利在法律上并非以“可执行的状态”存在,数据执法机关在实践中也很难将第22条作为切实可行的执法依据。实践中,对gdpr第22条的内在属性的认识割裂,在立法者和执法者之间渐次成型:立法者认为自己为数据主体创设了一种在特定情形中可以行使的权利,但执法者只将其视为针对特定类型自动化决策的禁令。与gdpr相对应的《欧盟执法指令》(下简称led)第11条针对特殊类型的自动化决策连续使用了三个“禁止”,显然是将gdpr第22条视为一条禁令,招来了多数成员国的质疑。从执法者的角度来看,禁令思维确实更易于执法活动的开展,也在表面上维护了gdpr与led的和谐统一。但此种“为了执行而执行”的粗浅认识罔顾了欧盟立法者在个人数据保护方面的大局观,强行以led第11条的规定去统合gdpr第22条的实现方式反倒会破坏欧盟整体数据保护框架的一致性。
在笔者看来,以权利思维而非禁令思维理解gdpr第22条,至少有三点好处:其一,承认gdpr第22条为数据主体可以行使的“脱离自动化决策权”,同第22条的字面表述相吻合,同时也符合立法者以法律规则“钳制”自动化决策过程的主观想象;其二,权利思维契合当下自动化决策被广泛应用于私营和公共部门的现实,对特定类型的自动化决策不宜一概禁止而应当考察其应用场景;其三,权利思维更符合辩证法所崇尚的自然科学观,即自动化决策完全可以给社会整体带来可观的利益,而非总是因外部性扩散催生社会成本。总而言之,以禁令思维理解gdpr第22条的做法过于简单,这其实是led其他条款也或多或少存在的共性问题,反映出人工智能领域立法者与执法者难以消磨的思维偏差以及由此产生的释法断层——可解释的法律不可执行、可执行的法律不合解释;如何尽可能缩小两者之间的差距,是在规则的应然和实然争辩之外,值得学术界和实务界上下求索的基础问题。
作为一项披着禁令外衣的权利,“脱离自动化决策权”本质上是一项请求权,是自动化决策关系中数据主体请求数据控制者“为或不为一定行为的权利”,数据主体不能对自动化决策的权利标的进行直接支配,而只能请求数据主体予以配合。由此引出了本文的关键问题,“脱离自动化决策权”究竟赋予了数据主体哪些请求数据控制者“为什么”与“不为什么”的权利?
长期以来,有关gdpr第22条所界定的权利性质、正当性与适用范围的争论从未停止,由此形成的学说千姿百态,其中存在两种常见的误解。一种误解是将gdpr第22条视为算法可解释性要求的圆心,与gdpr中“获解释权”的多个条款互为补强;另一种误解是将“脱离自动化决策权”与“被遗忘权”混为一谈,将数据主体脱离自动化决策的尝试等同于向数据控制者行使擦除个人数据的请求权。在应用层面上,将“脱离自动化决策权”视为数据主体请求“获解释”或者“被遗忘”的权利,具有一定的可操作性,实为将gdpr第22条作权利解的大前提下,权利思维向禁令思维有限度的靠拢的折衷之举。这两种不同的理解进路,正是导致“脱离自动化决策”被翻译为“反对自动化决策”或“不受自动化处理的决定的限制”的根本原因,也同时反映出各版本译者绝非生硬干涩地对原文进行单纯直译,而是在极高的人工智能法学造诣之上融入了自身对gdpr各条款的深入理解,缜密的法律思维可以从别具匠心的意译表达中窥见一斑。那么,“脱离自动化决策权”同“获解释权”“被遗忘权”之间的区别是什么?各权利之间的区别是虚是实?从权利思维出发,gdpr为即将到来的超级自动化时代建立了怎样的制度防火墙?“脱离自动化决策权”在自动化治理中的地位和功用是什么?

二
必也正名乎:三权并立的联动体系
本部分将从“脱离自动化决策权”同“获解释权”“被遗忘权”的差异入手,一则反思“脱离自动化决策权”的立法初衷;二则探讨“脱离自动化决策权”的实质内涵。
(一)“脱离自动化决策权”非“获解释权”之补强
大数据、云计算和人工智能技术的突飞猛进,“革命性地改变了网络空间内主体的能力差异和关系结构”,传统的法律制度难以应对技术黑箱掩映之下受众操控、信息寻租和监管套利的三重失控,对算法可解释性的合规要求应运而生。虽有学者反复指出,旨在提升算法透明度的硬性规定“既不可行,也无必要”,但在漫长的监管实践中,算法可解释性的合规要求还是成为了世界各国人工智能法律法规的核心要旨,即便是那些高度依赖事后问责机制的国家,也不否认算法可解释性实乃人工智能时代“对抗数据个体的主体性和自治性沦陷和丧失的内在之善”,是明确自动化决策主体性、因果性和相关性以确定和分配算法责任的重要前提。究其根源,在公众问责空前加强的年代,任何新技术的批量部署都必然被置于传媒与社会持续性互动的场域之中,以逐渐打消公众质疑、充分回应社情民意以及成功取得多数人同意为其合法性基础。
令人感到疑惑的是,在制定过程中反复强调算法可解释性有多么重要的gdpr,只在条例第5条第1款笼统地要求对涉及数据主体的个人数据,应以合法、合理、透明的方式进行处理。显然,公开透明的数据处理方式并不足以确保算法可解释性,顶多被视为算法可解释性众多构成要件中不可或缺的一环。实践中,人们不得不结合gdpr的序言,为算法可解释性要求寻找依据。gdpr序言第71条指出,接受算法自动化决策的数据主体应当享有“适当的保护”,因为潜在的机器错误和数据歧视极有可能给整个社会带来“偏见和不公”。第71条随即将“适当的保护”分为三类:一是获得人类干预的权利;二是表达异议和质疑的权利;三是获取相关决策解释的权利。就此而论,gdpr是从数据主体“获解释权”的进路出发,来反向构建算法可解释性的合规要求。佐证这一现实的依据是,gdpr第13条、第14条、第15条分别规定了直接从数据主体获得个人数据、间接从数据主体获得个人数据以及因各类原因访问个人数据的数据控制者向数据主体履行详细信息披露义务以及就特定事项进行进一步解释说明的义务,尤其是“决策过程所涉及的逻辑程序及其对数据主体的重要意义和可能影响”。
但是,从gdpr第13至15条引申出来的“获解释权”完全局限于数据的搜集和处理阶段,如此“事前解释”只能肤浅地让数据主体得知自己个人数据的处理概况和潜在影响,并不能让数据主体真正知晓最终形成的自动化决策与其当下际遇之间的因果关联。很明显,处于信息极度弱势地位的数据主体,主动行使“获解释权”的理想预期,是要获得其在承受自动化决策阶段的事中和事后解释,而gdpr对此语焉不详。在此种背景下,部分学者将gdpr第22条视为同第13至15条的衔接,补足了事中和事后“获解释权”的法律真空。
诚然,gdpr字面规定的“获解释权”确实存在事前、事中和事后脱节,导致权利难以覆盖自动化决策全过程的问题,但是,衔接断裂的问题完全可以通过直接补充规定的方式予以修复,实在没有必要在距离13至15条“至少7条开外的”第22条中以如此晦涩、隐蔽的方式对事中和事后的“获解释权”进行界定。欧盟立法者之所以不在gdpr中建立完整的“获解释权”链条,极有可能源于两个层面的思考和顾虑。其一,批评者们看到的是一个设定一项“获解释权”就可以让自动化决策可解释的世界,而这种理想愿景同当今技术运作的现实情况存在巨大鸿沟。尤其是在事中和事后阶段,随着机器学习模型的日益复杂、卷积神经网络的广泛适用、数据搜集源头的交汇重叠,要真正就自动化决策的运作原理与裁判机制作出详细且外行人也能理解的解释,可谓难上加难。事前的各类解释或许有助于数据主体作出是否同意自动化决策的判断,但考虑到人工智能是以技术手段对自然人的深度仿生,以预期效果为导向的、事中和事后的因果关联尝试极易将物质表象的经验规律同内在直觉的感性判断混淆起来,最终只能得到故弄玄虚、毫无根据的假设而非解释。其二,算法可解释性的合规要求,必然伴随相当可观的合规成本。“获解释权”的规定越是完整无遗漏,身处信息弱势地位的数据主体前期缔约和谈判的成本就越低,但因此增加的其他成本则完全由数据控制者或处理者概括承受。长期以来,对于此类成本转嫁是否合理的争论从未平息。一方面,正如上文所指出的那样,数据控制者针对自动化决策进行的事中和事后解释极有可能属于徒劳无功的解释,经常是“解释了也是白解释”;另一方面,完整意义上的“获解释权”至少在一定程度上有助于消弭算法歧视、降低数据控制者和数据主体之间的信息不对称。对于此类“或有或无”的法律规则,现代法经济学给我们的教义是:应当衡量法律实施的成本与潜在社会收益之间孰轻孰重,即那些看似公平的原则是否同时也是那些符合效率的原则。在全球人工智能竞争白热化的阶段,说服各国政府和跨国大型公司建立事前、事中和事后的“获解释权”闭环实属痴人说梦。
(二)“脱离自动化决策权”不与“被遗忘权”混同
在“脱离自动化决策权”难同“获解释权”等量齐观的情况下,另有一些学者试图将gdpr第22条视为“被遗忘权”相关条款的延伸乃至重复。因为在历史上,“被遗忘权”的创设同“脱离自动化决策权”的发展有着千丝万缕的联系。
在2010年google spain v. costeja gonzalez案中(以下简称谷歌案),原告要求被告谷歌公司删除12年前因为房屋网络拍卖而在搜索引擎中陈列的、已经过时的个人信息。欧盟法院在裁判时,从dpid中推导出了数据主体应当享有的“被遗忘权”,依据是第6条“个人数据的处理应当适当、相关、同被处理(以及进一步处理)的目的吻合,在必要时进行更新以保证准确性”以及第12条允许数据主体“更正、擦除以及屏蔽不符合dpid所规定的处理的数据”。2013年欧盟《信息安全技术公共及商用服务信息系统个人信息保护指南》吸收了欧盟法院的判决和dpid的前述规定,直截了当地建议:“当数据主体有正当理由要求删除其个人数据时,应及时删除个人数据。”gdpr第17条对“被遗忘权”进行了直接规定:“数据主体有权要求数据控制者擦除关于其个人数据的权利。”
“被遗忘权”与“脱离自动化决策权”的混同,源于谷歌案引发的有关搜索引擎性质的争议。一方认为,搜索引擎只是数据的媒介,而非严格意义上的数据控制者或者处理者,一如谷歌的首席法律顾问沃克在接受《纽约客》采访时所言:“我们不创造信息,只是让信息变得可访问。”另一方则针锋相对地指出,搜索引擎在信息处理方面并非全然被动,结果的呈现方式与先后次序,即是搜索引擎处理数据后形成的自动化决策。从搜索引擎公司“竞价排名”的常见盈利手段来看,显然后者的观点更有说服力。将搜索引擎确认为数据控制者,可以推导出一个能够达成共识的认知,即谷歌案中原告向谷歌公司行使“被遗忘权”,是希望谷歌公司能够对特定搜索结果进行人工干预,实现“脱离自动化决策权”的行权效果。应原告诉求进行人工干预的结果并非真正让原告在网络世界中“被遗忘”,而是让谷歌的搜索界面不再将原告已经过时的信息纳入排序算法。也即是说,作为数据主体的原告行使“被遗忘权”拟达到的效果实际上是脱离搜索引擎的自动化决策。此种做法自欺欺人的地方体现在,搜索引擎没有办法、也没有权力真正删除所有包含数据主体希望被遗忘信息的页面,而只能将这些页面在搜索结果中隐去,如果在地址栏中输入这些页面的网址,仍将能够打开这些页面。需要注意的是,有不少热门网站专门记录谷歌删除或移除掉的链接,例如hidden from google、wikimedia和reddit等,使得希冀行使“被遗忘权”的数据主体常常陷入越描越黑的境地,即使脱离了搜索引擎的自动化决策也脱离不了“好事者竟趋焉”的无事生非。在这个意义上,“脱离自动化决策权”似乎是行使“被遗忘权”的主要手段,也是行使“被遗忘权”能够实现的最低目的,部分学者将gdpr第22条视为对第17条“有益而有必要的重申”就不足为奇了。
但是,“被遗忘权”并不能在所有情形中都等同于“脱离自动化决策权”。只需在谷歌案的基础上稍微做一点延伸,就能理解“被遗忘权”的独特之处。原告向谷歌公司行使“被遗忘权”,最终只能达至“脱离自动化决策权”的效果,这是由于搜索引擎的特殊性质所决定的。如果希望达到被彻底遗忘的效果,原告应该一一向刊登原告个人数据的页面所有者行使“被遗忘权”。这些被搜索引擎直接抓取的页面,是纯粹的信息刊载或转载方,几乎不涉及自动化决策,只需简单地从服务器中删除页面,即可履行数据主体的被遗忘请求。这个过程虽然也涉及人工干预,但同行使“脱离自动化决策权”有着天壤之别,是以删除内容、移除链接作为权利行使的主要法律后果。实际上,搜索引擎要想完全履行数据主体的被遗忘请求,除了以人工干预的方式将数据主体从自动化决策中剔除出去之外,还需要在其服务器中一一手动删除相关页面的快照,且删除过程的工作量甚至不低于脱离过程的工作量。在上述认知的基础上,还要强行将“被遗忘权”与“脱离自动化决策权”混同,就显得不合时宜了。
(三)gdpr权利体系重构:回归序言第71条
归根结底,“获解释权”和“被遗忘权”各自具备深刻的内涵和外延,是与“脱离自动化决策权”截然不同的两种权利。然而,行使这两种权利确实在一定程度上也能让数据主体“脱离自动化决策”,由此引发的问题是,“获解释权”和“被遗忘权”是否可以被反向视为“脱离自动化决策权”的被动权能和主动权能?易言之,gdpr第13至15条以及第17条,是否是第22条的两种不同行权方式?答案无疑是否定的。
1.“获解释权”的补强条款:gdpr第35条
首先来看为什么“获解释权”并非“脱离自动化决策权”被动权能。理论上,火力全开的“获解释权”,确能为“脱离自动化决策”结果的实现,提供较强助力,因为只要数据控制者或处理者不能向数据主体提供合乎情理的行为解释,那么数据搜集和处理将失去正当和合法性——作为程序运行“燃料”的大数据一旦断供,自动化决策将不复存在,数据主体便自然实现“脱离”。但正如本文第一部分所指出的那样,gdpr第13至15条只规定了数据主体的事前“获解释权”,数据主体在行使这种权利的时候自动化决策尚未发生,自然也就没有“脱离自动化决策”可言。同时,出于对效用的追求,欧盟立法者具有维持弱式“获解释权”的激励,不会贸然赋予数据主体全过程链的“获解释权”。
在第13至15条规则圆满性难以为继的情况下,毋宁以gdpr第35条数据控制者和处理者的“数据保护影响评估义务”作为其事中和事后补强:当用户侧写可能对数据主体的权利和自由带来高风险时,数据控制者或处理者必须在“充分考虑数据处理性质、范围、语境和目的的基础上”,评估自动化决策将对个人数据保护造成的影响。第35条对事中和事后算法可解释性要求的补充体现在三个方面:其一,数据保护影响评估要求对数据处理的可能操作和计划目的进行系统性描述,形成文字的系统性描述以数据控制者所追求的正当利益为主要内容;其二,数据控制者必须对数据的搜集和处理的必要性与相称性进行阐述,即用户侧写应以数据控制者的正当利益为限,未经数据主体同意不得牺牲其权利;其三,当数据主体的正当权利和数据控制者的正当利益存在此消彼长的张力时,数据控制者必须在数据保护影响评估中表明可以采取的应急性风险应对措施,包括但不限于gdpr已经规定的法律保障、安全措施和激励机制。从条文结合可以产生的效果来看,第13至15条主要是要求数据控制者和处理者就事前数据挖掘的信息来源、典型特征和分类办法以及算法程序的运作机理、代码逻辑和预期效果进行事前解释,第35条则是要求其就事中的系统偏差、运行故障和矫正机制予以说明,这实际上只是在最低限度实现了算法可解释性的显化,并且由于事后解释的要求仍然孱弱,数据主体行使“获解释权”最多只能得到一个看似将人工智能载体的硬件、软件和数据处理之间的相互作用如何导致自动化决策之间因果关系阐明的解释。如果心怀善意,数据控制者或处理者给出的是“自以为正确的解释”。如果别有用心,解释和说理的方式将完全取决于拟实现的经济或政治目标。在这个意义上,gdpr第13至15条与35条的结合,勉强构建了多重弱化但相对全面的“获解释权”。
2.“被遗忘权”的上位条款:gdpr第21条
上观号作者:上海市法学会